Validating data workloads post migration: 8 critical challenges and solutions
Automated validation as a critical strategy for end-to-end data platform modernization
Inefficiencies in cloud migrations increase enterprises’ annual migration spend by 14% on average. When tallied globally, this adds up to more than $100 billion in wasted spend over the course of migration in three years.
Most enterprises cite the costs around migration as a major inhibitor to cloud adoption. While many factors lead to delays and spiraling costs, one of the most prominent causes of cloud migration failures is the inability to validate the migrated workloads thoroughly.
Legacy data warehouse, ETL, and analytics systems migration typically include DML scripts and queries, procedures, ETL scripts, orchestration scripts, jobs, etc. These needs thorough validation at unit and integration levels to be certified as production-ready for the target platform.
However, validation of transformed workloads post-migration is a tricky task. Although it might seem straightforward while testing at a query level or against a sample dataset, it may not cover all possible scenarios at a productionized job level. Furthermore, any error in the transformed code can derail the entire migration and lead to spiraling costs and time. Therefore, it is necessary to scrutinize the converted code to validate them before making them live.
How do you ensure thorough validation of your workloads to go live confidently post migration?
Based on extensive migration experience with Fortune 500 customers for over a decade, we have collated a list of the 8 most complex challenges and corresponding solutions for effectively validating the migrated workloads.
Challenge #1: Uncertainty about coverage of all use cases
First encountered when the testing phase starts, users often discover unresolved issues in the transformed code. For instance, the code might not cover corner cases or appear correct without meeting its holistic functionality. That’s why holistically checking the overall logic in an integrated fashion becomes crucial.
Solution: Leverage automation for thorough validation of all the test cases
Auto-generated reconciliation scripts can thoroughly scrutinize and verify the transformed queries (EDW), components (ETL), and Hadoop workloads – along with conditional and orchestration logic at a job level for the entire enterprise dataset. An automated migration tool can validate the required quality levels through maximum automation and eases the job of the Quality Assurance (QA) team.
Challenge #2: Limited availability of test data
The complete test data must be available to ensure all the relevant queries are validated and the output gives a meaningful dataset based on the input query. However, enterprises are sometimes reluctant to share sensitive data, and only a subset of data is available for testing the transformed scripts. This makes it difficult to certify all the scenarios and can become an obstacle to validation.
Solution: Auto-generate relevant datasets
An automated migration accelerator capable of auto-generating sample datasets based on complex query conditions can help, especially in unit testing. Instead of letting data unavailability become a showstopper, use a validation approach where the system auto-generates the required data and validates the transformed code against it. Please note that the algorithm working in the background to generate the relevant dataset should be highly efficient.
Challenge #3: Multiple validation cycles at every stage and for different use cases
There can be multiple validation scenarios based on data availability, like the baseline data, incremental on top of baseline data, secured through regulatory PII encryptions, at a level of post-ETL processing, or in cloud data warehouse tables. It may also be scattered across legacy data warehouses and cloud data lakes. These multiple scenarios can affect the validation process without an effective (automation) strategy.
Solution: Devise a dynamic strategy to reconcile at every stage
To overcome this roadblock, start with system extensibility and configurability. Then, reconcile at every step of the migration lifecycle as the dataset is changed or modified at every stage. First, validate the baseline data and then perform iterations with the data increments incorporated in the dataset. Once completed, you can validate the encrypted data (for instance, the PII-compliant dataset) in the next step. This staggered and stepwise approach ensures any deviances are identified and rectified early.
After the ETL scripts are executed, compare the results for discrepancies. Then package all the conditional and orchestration logic as jobs to validate the processed data once loaded into the cloud data warehouse. Once the validation is successful at the job level, you can assume they are good to go for productionization.
Baseline data
With increments
Encrypted dataset
Post-ETL processing
Cloud data warehouse
What to do in case of these exceptions?
- Data in the legacy data warehouse – Perform validation between the source and target. If it is already a part of the target system, have a target-to-target comparison mechanism in place
- Source data in cloud data lake like S3 or ADLS – Read the tables from the data lake and compare them with those on the target side
- Data in files like S3 buckets – Leverage file-to-file validation for comparing and validating the files
Pro tip:
Consider creating copies of the original data in advance so you can revert to it in case of unexpected events. Also, deal with those scripts at one point with different target tables to avoid conflicts. Dealing with the scripts that are modifying the same tables may pose some discrepancies, and hence the validation results may be flawed.
Challenge #4: Root cause analysis of a failed script in validation
While validating a script and its output against our data, it becomes challenging to identify the exact query which is erroneous. This makes it tiresome to track what to debug and locate the precise issue.
Solution: Enhance the system’s ability to identify the exact erroneous query in the script for efficient debugging
A well-designed validation architecture or service can help you pinpoint the exact erroneous query and get to its root cause. In case of any issues, the developers should know which query in the script is responsible for the mismatch. For example, look at the column mismatch and map it back to the query that uses it or update any information in that column.
Challenge #5: Validation is too time-consuming for large tables
Validating large tables can be time and effort-consuming. For example, some tables may take hours to report a problem within a query or with a particular script, which can be problematic while dealing with large volumes of data. Hence, it would be best to have a foolproof mechanism to deal with this effectively.
Solution: Implement a staggered approach
A staggered approach is best for validating the transformed code against large datasets. First, perform a row-to-row comparison. If it matches, move to aggregate function-based validation like sum, average, count, distinct count, min, max, etc., and perform a cell-to-cell comparison on a subset of data. Afterward, perform an exhaustive cell-to-cell comparison on the entire enterprise dataset. Fix the discrepancies at every stage so it will take less time to validate the whole dataset.
Table-level validation is also helpful in validating the functional accuracy of the converted ETL scripts.
Challenge #6: Unavailability of key columns
In some cases, key column information is unavailable, which is essential to perform a cell-to-cell comparison to validate the transformed workloads at the minutest level.
Solution: Create a row hash
If you have information about key columns, leverage it to differentiate the mismatched records. However, if it’s unavailable for specific tables, create a row hash for row-level comparison.
Challenge #7: Lack of cell-level validation leading to delay in production
It’s quite hard to validate datasets at the cell level to guarantee production readiness. This is because it is not straightforward for a variety of use cases, concurrent usage, connection to cloud systems, choice of engine for the performance of processing the records, taking certain exceptions for columns like Null, Blank, etc., performing file-level validation, unavailability of key columns and likewise. Therefore, the system must have the capability to cater to the minutest verification strata for maintaining data consistency.
Solution: Go step-by-step to the minutest level
After completing validation at the row and the aggregate function level, go for a cell-to-cell comparison on a subset of data to identify mismatches in records. Subsequently, perform an exhaustive cell-to-cell comparison on the entire enterprise dataset. A cell-by-cell validation provides incredible go-live confidence and quality assurance for production. LeapLogic can help with cell-level comparison and validation and produce the corresponding results.
Challenge #8: Validation of analytics models
As per an article from McKinsey on Model Risk Management (MRM), banking and financial institutions are driving towards becoming model risk management organizations to be more effective and value-centric. However, the primary risk lies in defective models and model misuse. This may lead to operational losses, which may turn into billions.
Solution: Mature MRM removes model uncertainties and increases transparency
Enabling an MRM strategy for risk management of analytical models for SAS workloads is crucial. This helps improve quality and maintain consistency requirements. The same McKinsey post also describes that automation of well-defined and repetitive validation tasks, such as standardized testing or model replication, can further lower costs.
Conclusion
While many undermine the significance of validation, it is necessary to ensure optimal performance of the migrated workloads in the cloud. The right tool ensures that apart from the optimized flow, all the scenarios and corner cases have been validated and perform optimally in production.
LeapLogic offers end-to-end validation as a part of its modernization service. It addresses all the above-listed challenges efficiently and offers out-of-the-box functionalities to attain your modernization goals.
A snapshot of its configuration screen is given below.
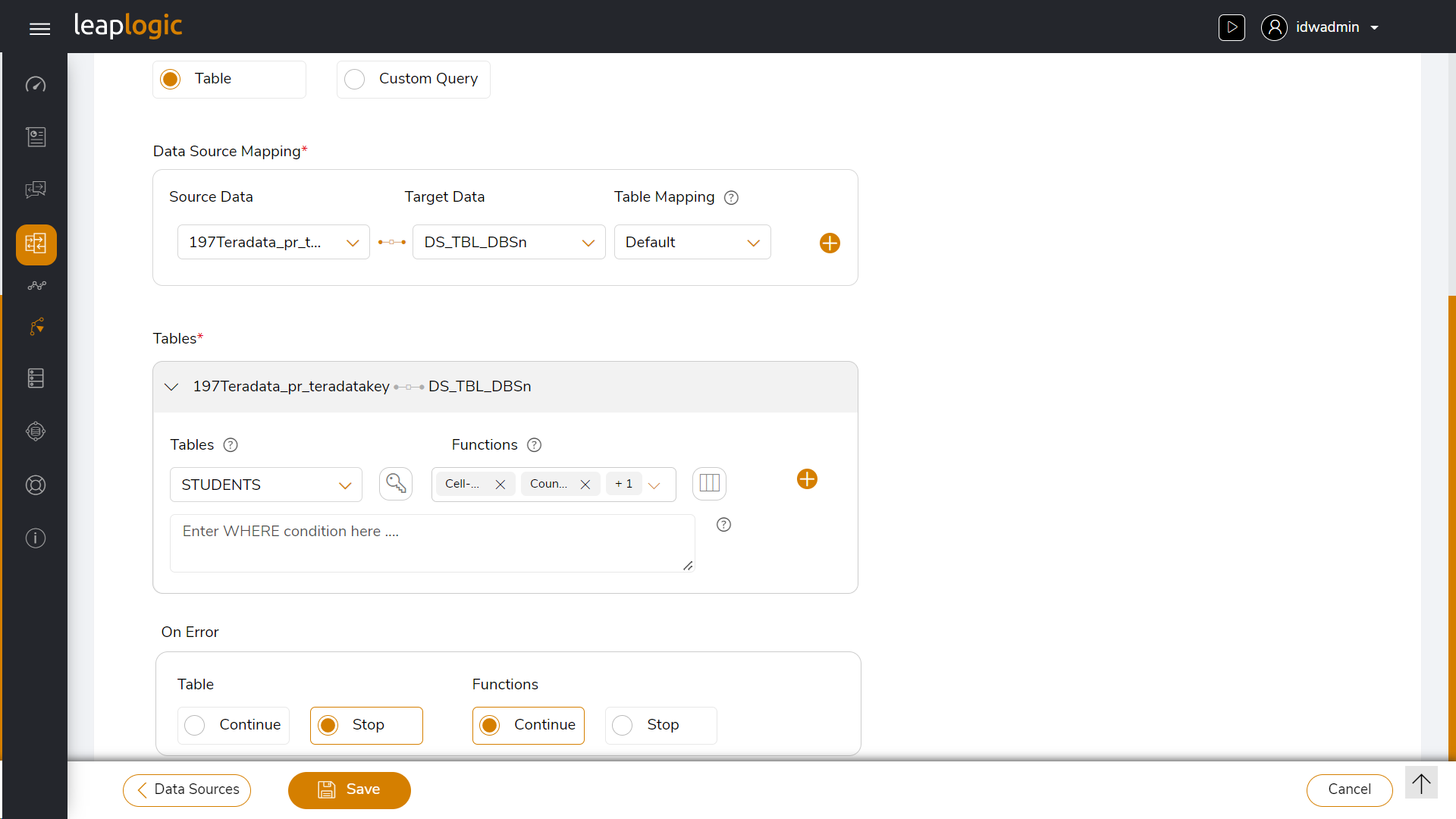
LeapLogic certifies 100% of the transformed workloads at all levels in the transformation cycle and performs comprehensive reporting of surplus and mismatched records with dedicated color coding. Its validation is mature, performant, and resilient due to its vast experience in dealing with various use cases and enterprise scenarios.
A screenshot of its reporting is given below.
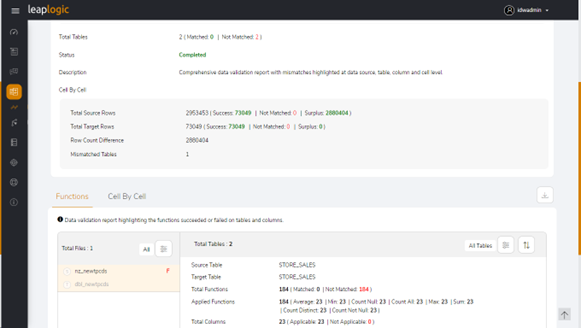
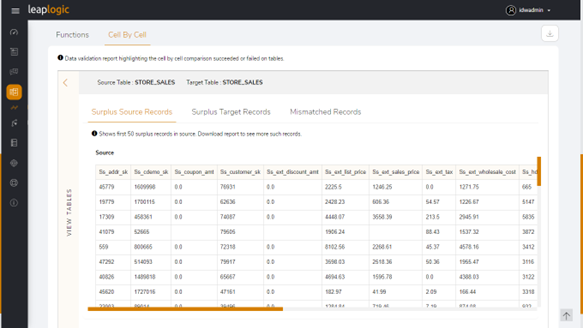
Validation is just one part of the modernization journey, but it can be the most crucial aspect for attaining your holistic transformation goals in the long run. Explore LeapLogic to learn how we deliver metric-moving outcomes by empowering our customers throughout the modernization cycle.
To learn more, book a demo or start your free trial today.

