
7 best practices to modernize data architecture on Databricks with LeapLogic
Authors:
Abhijit Phatak, Director of Engineering, Impetus
Soham Bhatt, Modernization Practice Lead and Lead Solutions Architect, Databricks
A Lakehouse is a new-age, open architecture that combines the best components of data lakes and data warehouses, enabling enterprises to power a wide range of analytics use cases – from business intelligence (BI) to artificial intelligence (AI).
The Databricks Lakehouse Platform simplifies data architecture, breaks down data silos, and provides a single source of truth for analytics, data science, and machine learning (ML).
While data lakes excel at processing massive amounts of data at low cost, the Databricks Lakehouse addresses data reliability and ease-of-use constraints by adding data warehousing capabilities like:
- ACID compliance
- Schema enforcement and governance
- Open collaboration
- Support for diverse types of workloads
- Fine-grained security
- Update/delete/merge functionality
- Extensive ANSI SQL support
- A super-fast BI querying engine
The platform also provides native integration with MLflow – an open source platform for managing the end-to-end machine learning lifecycle.
LeapLogic, a cloud transformation accelerator, helps enterprises modernize legacy data warehouses, ETL, SAS, and Hadoop workloads to the Databricks Lakehouse. This blog discusses the best practices for ensuring a seamless transformation journey with LeapLogic.
1. Strike a balance between ‘lift and shift’ approach and total refactoring
While strategizing the move to Databricks Lakehouse, many enterprises face the dilemma of adopting a ‘lift and shift’ approach or total refactoring. A simple ‘lift and shift’ may sound intuitive and simple, but the existing technical debt can get carried over to the target. And there is no opportunity to re-architect and refactor the application for the cloud. At the same time, total refactoring prolongs the time-to-market as it requires re-architecture, additional development time, and extensive training of resources on new processes and technologies.
LeapLogic strikes a fine balance between these two approaches.
It performs a comprehensive assessment to identify the technical debt and dependency structure across workloads, pre-empt performance optimizations, and provide target-specific recommendations. LeapLogic reverse-engineers logic from the code and data model and determines candidates for ‘as-is’ migration and refactoring.
2. Analyze workload usage patterns and dependencies to prioritize use cases
One of the toughest decisions in the modernization journey is finalizing the migration sequence of workloads and applications to the Databricks Lakehouse.
Performing an in-depth, pattern-based analysis of the existing workloads helps unlock data-driven insights and prioritize high-value business use cases. In addition, a comprehensive, end-to-end data and process lineage helps visualize complex interdependencies between all the workloads in a simplified manner.
Data lineage helps identify the complete chain of input and reference tables that are used to populate the output tables. Additionally, process lineage shows the linkages between scripts, procedures, jobs, and any other piece of code calling/called scripts, etc.
LeapLogic automates workload assessment and empowers enterprises with 360-degree visibility – from data collection, ingestion, and ETL to curation and consumption. This, in turn, helps create a robust blueprint for phase-wise migration to the Databricks Lakehouse and eliminates the risks associated with a ‘big bang’ approach.
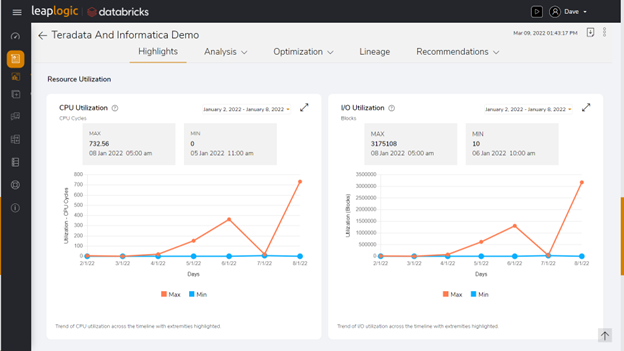
Sample assessment screenshot
3. Identify and resolve technical debt in existing systems
To ensure optimal price-performance ratio on Databricks, it is important to identify optimization opportunities within the existing legacy system at schema, code, and orchestration levels during the migration. In addition, the schema needs to be structured and modeled following Delta Lake’s best practices.
For instance, LeapLogic automatically converts database indexes, and specialized features like Teradata single-AMP joins or Azure Synapse columnar storage and distribution. It converts these to Databricks Delta-compliant DDL with code optimizations such as Delta Lake Z-Ordering, Bloom filter indexing, and partitioning/clustering.
Once the schema is optimized, any anti-patterns in the code (at the file or query level) must be identified and resolved, as these impact query performance adversely, particularly in larger datasets.
For orchestration, the logic in scheduling scripts or jobs may need to be broken down to execute independent jobs or queries in parallel. This helps significantly improve performance compared to sequential execution.
Additionally, the AQE framework, available in Databricks Runtime 7.0, reoptimizes and adjusts query plans based on runtime statistics collected during query execution. As a result, it chooses the right moment to optimize Spark SQL and helps speed it up at runtime.
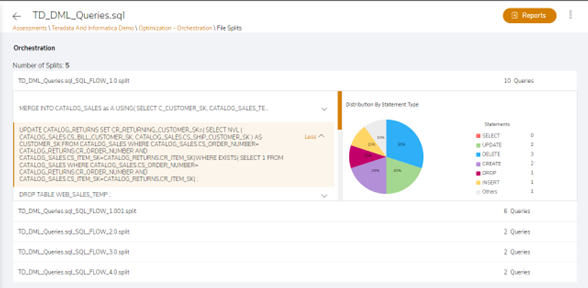
Orchestration dependency structure: A graphical representation
4. Plan an effective future-state architecture
A flexible, optimally designed data architecture helps enterprises efficiently address complex use cases, power advanced analytics, and meet business SLAs.
LeapLogic helps businesses design a resilient, high-performant Lakehouse architecture based on various considerations, including security, cost, and operational efficiencies.
Here’s a closer look at LeapLogic’s step-by-step approach:
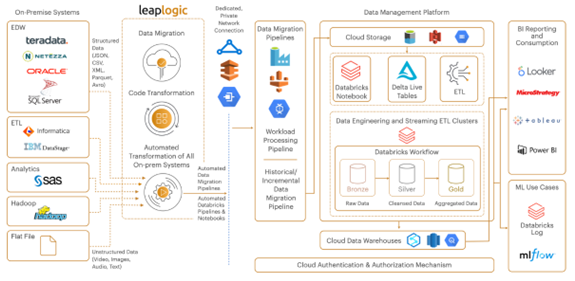
Sample Databricks architecture diagram
- All on-premises systems (including data warehouses, ETL systems, analytics systems, Hadoop, and flat file sources) are transformed into a Databricks-native stack
- Data migration pipelines, Databricks pipelines, and notebooks containing the transformed logic are created automatically
- A dedicated, private connection is established to transfer data securely from the on-premises network leveraging Express Route/AWS Direct Connect/Cloud Interconnect
- The workload processing pipelines are then executed using Databricks jobs and Workflows and the data is ingested into Delta Lake
- The transformed data warehouse and ETL code are automatically validated through auto-generated reconciliation scripts and executed via Databricks Notebooks
- The raw data is processed and made consumption-ready, leveraging Databricks ETL workflows. Given the performance improvements of Databricks SQL, most BI reports can run directly on Databricks’ Gold/Presentation zone. This enables self-service analytics across the entire Lakehouse.
- Cloud authentication and authorization mechanism is implemented to ensure secure access to resources and applications.
- The data management platform, powered by Databricks Lakehouse, is also integrated with the consumption layer, where the aggregated data is used for BI reporting.
5. Transform workloads end-to-end, including business logic
Data migration is an important first step of the data estate modernization journey. But to realize the full ROI on modernization, it is vital to migrate the complete source code with the business logic. The complexity lies in migrating and modernizing code like stored procedures, ETL scripts, Shell scripts, analytics code such as SAS scripts (if any), and orchestration code (Control-M, AutoSys, etc.)
LeapLogic handles these transformations easily and supports Databricks innovations like Delta Live Tables, the new SQL Photon Engine, etc.
Here’s an example of how LeapLogic performs end-to-end automated transformation of workloads:
Data warehouse and ETL:
- Legacy DDL scripts are converted to Delta tables
- SQL scripts and procedural logic are transformed to a Lakehouse-native form like Databricks SQL, PySpark
- Scheduler/ workflow scripts like Control-M/AutoSys/EPS/Cron Shell are transformed automatically to Databricks-native scheduler Workflows.
- Shell scripts with embedded Teradata blocks are converted to Lakehouse-compatible Shell scripts + Spark SQL
- Built-in functions of the data warehouse are transformed to Lakehouse-native functions.
- ETL scripts are converted to Lakehouse-native code in PySpark in the form of executable Notebooks
- Legacy BI/consumption reports are transformed into modern reporting engines of choice such as Power BI, QuickSight, etc.
- Schema and code are optimized with embedded Spark performance tuning parameters.
SAS analytical scripts:
- Legacy DDL scripts are converted to Delta tables
- SQL scripts and procedural logic are transformed to Lakehouse-native code like PySpark
- Business logic contained in procedural statements and macros are transformed to Lakehouse-native code like PySpark
- Built-in SAS PROCs and analytical functions are converted to Lakehouse-native or custom functions using a rich library provided as part of the deliverables
- SAS analytical workloads like data prep/acquisition (macros, data steps, conditional logic) and advanced PROCs/models are converted to Lakehouse-native code (PySpark)
The transformed code is then validated and certified on the Databricks Lakehouse using a repeatable, verifiable, and extensible framework.
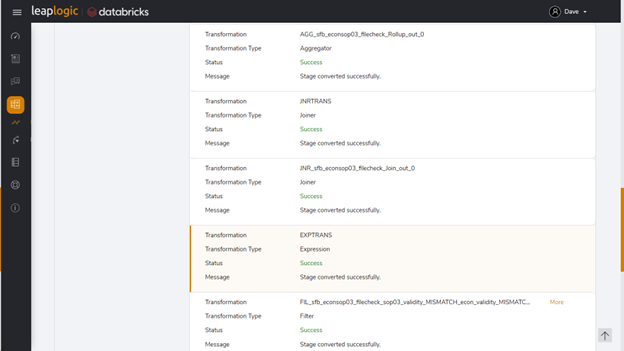
Example of Informatica ETL script conversion
6. Cutover planning and decommissioning
Modernization initiatives aim at transitioning the legacy system capacity to new-age data architecture and instantly tapping the myriad benefits of Databricks. However, myopic planning can lead to a cutover disaster and completely derail project goals.
LeapLogic helps enterprises implement a robust, phased migration strategy and decommission the migrated code seamlessly after extensive testing and productionization in the new environment.
Decommissioning helps quickly limit cloud costs, ensure on-time project completion, and mitigate any risk of rolling back to a previous version.
Therefore, generally, it’s a good idea to move in phases rather than big bang. Proper phased planning based on actionable assessment insights helps in a smooth cutover.
7. Operationalize migrated workloads over Databricks Lakehouse-native services
The last leg of migration involves operationalizing the migrated workloads in the Lakehouse environment. This enables a smooth transition into production and helps the enterprise go live.
Operationalization includes:
- Target platform stabilization through a minimal parallel run period
- Workload productionization
- Setting up DevOps and CI/CD processes
- Integrating with third-party tools/services
- Configuring proper cluster types and templates
- Enabling options for auto-scaling
- Ensuring auto-suspension and auto-resumption
- Optimizing the cost-performance ratio
Enterprises also need to set up security policies and protocols (such as SSL and AD integration), define regulatory compliance standards, and set up tools for lineage, metadata, etc.
LeapLogic takes advantage of implicit data governance and performs these steps automatically through infrastructure as code while adhering to a specified project management methodology (like Agile).
To accelerate DevOps, it handles defects, ensures code packaging and check-ins into SCM, enables version control, and manages universal artifacts.
Final thoughts
The promise of the cloud is compelling IT and data teams to take a hard look at their current systems and evaluate what they need to make this promise a reality. However, the path to modernization can be challenging and disruptive.
Most companies are concerned about the decades of efforts and investments they have put in for writing and refining legacy system code. Also, with such legacy systems, there is often inadequate understanding of the complete logic, with only partial documentation available.
The need for customized use cases and exceptional security and compliance needs adds to the complexity. This is where migration accelerators like LeapLogic help customers modernize their legacy data warehouse, ETL, and analytics with ~70-90% automated code conversion and productionization on Databricks Lakehouse.
LeapLogic has helped several Fortune 500 enterprises transform to Databricks faster, with more accuracy, and experience the freedom of the cloud without any business disruption.

