
3 reasons why lineage should be an integral part of your modernization journey to Databricks
To implement trust-based governance, enterprises should acknowledge the different lineage and curation of assets. – Gartner
A comprehensive, end-to-end data and process lineage is quintessential for effectively planning the migration of legacy workloads to the Databricks Lakehouse.
Lineage helps visualize complex interdependencies between all the workloads in a simplified and intelligible manner.
For example, data lineage helps identify the complete chain of input and reference tables used to populate the output tables. Additionally, process lineage shows the linkages between scripts, procedures, jobs, and any other piece of code calling/called scripts, etc.
This blog takes closely examines why lineage plays a critical role in modernizing ETL, data warehouse, and analytics systems to the Databricks Lakehouse.
#1 Enables end-to-end analysis of the existing codebase
Even within one line of business, multiple data sources, entry points, ETL tools, and orchestration mechanisms exist. Decoding and translating this complex data web into a simple visual flow can be very challenging during large-scale modernization programs.
Here’s where a visual lineage graph adds tremendous value and helps define the roadmap to the Databricks Lakehouse. It deep dives into all the existing flows, like orchestrator jobs, applications, ETL scripts/workflows, BTEQ/Shell (KSH) scripts, procedures, input and output tables, columns, and provides integrated insights.
These insights help data teams take strategic decisions with greater accuracy. Enterprises can proactively leverage this integrated analysis to mitigate the risks associated with migration and avoid business disruption.
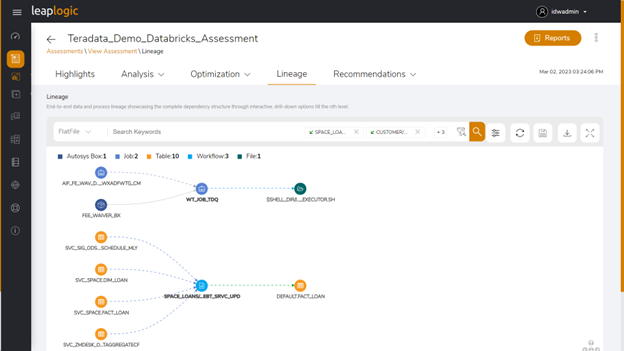
#2 Helps segregate workloads into logical units for migration
Advanced tools supporting an end-to-end modernization charter provide sophisticated assessment capabilities like interactive lineage (a graph) using a repeatable and verifiable DAG-based approach. This helps segregate interdependencies into logical units based on the level of business-criticality of applications/users.
Enterprises can then scope their migration to the Databricks Lakehouse into logical phases and offload legacy workloads in a phased manner rather than adopting a ‘big bang’ approach, which is more risky. IT leaders can make informed decisions on workloads that can be migrated as-is, need optimization, and complete re-engineering.
#3 Provides 360-degree visibility – from origination to reporting
Lineage also helps trace the complete data flow in steps. The visual representation helps track how the data hopped and transformed along the way, with details of parameter changes, etc. Automated transformation tools that provide backward and forward lineage show the hops and reference points of data lineage with complete audit trail of the data points of interest.
They also help temporarily ignore peripheral, unwanted data points like system tables, bridge tables, etc. and establish valuable correlations between data points to uncover hidden patterns and results. Users can also deep dive into specific flows leveraging next-gen features like contextual search, advanced filters according to workload type, an interactive visual interface, graph depth, and more.
These capabilities help businesses plan a seamless migration and modernize their ETL, data warehouse, and analytics systems faster to the Databricks Lakehouse stack, with lower cost and minimal risk.


